
探寻 Agent 决策中枢:迈向确定性执行的规划范式
摘要总结:如果说 LLM 是 Agent 的大脑,规划模块则是其负责复杂决策的“前额叶”。本文深度解构了 Agent 迈向确定性执行的核心路径:从任务分解的降低熵值,到自我反思的闭环控制。通过对比“边走边看”的 ReAct 动态响应模式与“谋定后动”的 Plan-and-Execute 预编排模式,本文揭示了如何针对长链路工程任务构建稳健的决策范式,助你完成从“简单提示词”到“复杂架构设计”的认知跃迁。
1. 引言
在人类大脑中,前额叶皮层负责复杂的认知规划、决策和社交表现。对于一个 Agent 而言,规划模块正是它的“前额叶”——它决定了 Agent 是只会机械响应指令的“木偶”,还是能独立拆解目标、在复杂环境中寻找最优路径的“数字员工”。
Agent 的规划能力主要由两部分协同驱动:任务分解与自我反思。
2. 任务分解:化繁为简的策略
任务分解是指将一个复杂的目标或任务拆解为多个具体、可操作的的子任务,以便 Agent 能够更高效地执行和管理。其本质是降低问题的熵值,让 Agent 能够聚焦于每一个细小的确定性步骤,从而逐步解决问题,提高规划的可行性和执行效率。
根据“规划”与“执行”发生的时间节点,业界形成了三类主流方法。
2.1 先分解后规划
这种模式类似于“建筑图纸制”,先将复杂任务拆解为多个子任务,然后再为每个子任务制订详细的执行计划,确保Agent 在动手之前,必须产出完整的步骤清单。其核心逻辑是先将任务细化为子任务,并明确依赖关系。
先分解后规划的优势在于任务与原任务联系紧密,能有效降低任务遗漏和幻觉风险。它的不足在于缺乏灵活性,一旦初始计划中的某一步在执行时受阻,由于计划已固定,整个流程容易陷入死循环或彻底失败。因此,在工程实践中,我们必须深入思考如何设计动态调整策略或引入人工干预节点,以规避问题。
2.2 边分解边规划
这种模式类似于"摸着石头过河",让推理与行动交替进行。Agent 不预设固定的执行路径,而是根据每一步的反馈动态调整,在分解任务的同时进行规划,实时优化子任务的执行顺序和策略。
分解边规划的策略能实时响应环境反馈,根据环境反馈调整分解策略,容错率高,具有较好的灵活性和适应性。但是,在处理复杂任务时,如果整个规划过程过长,可能会因为 LLM 上下文过长而产生“幻觉”,导致后续的任务与规划偏离初始目标。
2.3 基于语言模型的自主分解
这是一种更纯粹的模式,利用 LLM 强大的语义理解能力,直接通过 Prompt 引导其生成管理子任务的指令,将自然语言目标转化为机器可理解的步骤树。
它的核心逻辑是直接将自然任务细化为子任务,无需预设计划。这种模式虽然简单,但是需要 LLM 具备强大的语义理解能力,才能准确地将自然语言目标转换为子任务。同时,由于 LLM 生成的子任务是基于当前环境反馈的,因此在处理复杂任务时,可能会因为环境变化而产生“幻觉”,导致后续规划逐渐偏离初始目标。
3. 自我反思:闭环控制的艺术
在 Agent 规划模块中,反思(Reflection)是一个重要的概念,如果说任务分解是“进攻”,那么自我反思就是“防守”与“修正”。它是一种提升 Agent 运行成功率的核心提示策略,通过模型的自我审查来改进初步成果。
反思的基本原理是通过模型的自我审查和自我反馈来改进初步生成的内容,反思机制也通常遵循一个“生成-评估-修正”的循环:
生成阶段:模型产出初步的解决方案(如一段代码或一份大纲)。
反思阶段:模型切换为“审计员”角色,对照用户需求和客观约束,找出初步结果中的不足、逻辑漏洞或错误。
修正阶段:基于反思建议,重新组织结构或调整细节,产出更高质量的最终版本。
在每一轮反思中,AI 模型会回顾生成的内容,评估其质量,并提出修改建议。这些修改建议可以是细节上的调整,也可以是对生成结构的重新组织,目的是提升内容的连贯性、逻辑性、表达清晰度或增强对用户需求的适应性。
为了让这种“自我纠错”能力规模化,业界也演化出了几种成熟框架:
Reflexion:赋予 Agent 动态记忆能力,通过回顾过去的失败经验来优化当下的决策。
CoH (Chain of Hindsight):向模型展示带有正面和负面反馈的历史输出,通过对比学习,鼓励模型在当前任务中“趋利避害”。
4. 动态响应模式:基于 ReAct 看规划闭环
在众多 Agent 设计模式中,ReAct (Reasoning + Acting) 是目前应用最广、直观性最强的模式。它完美体现了前文提到的“边分解边规划”策略,通过将推理(Reasoning)与行动(Acting)深度耦合,让 Agent 具备了在复杂环境中“小步快跑”的能力。
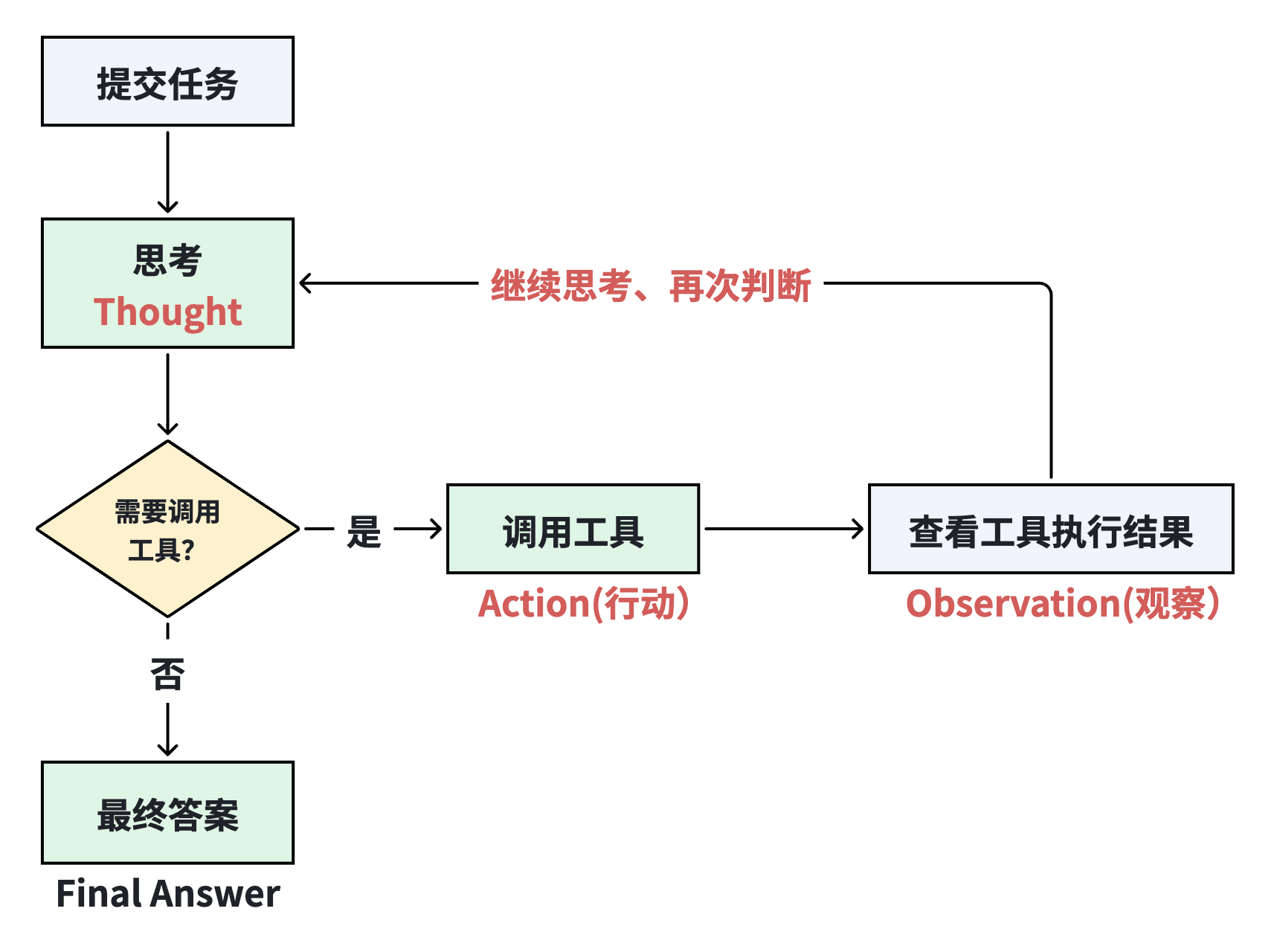
- 推理(Reason):这是思考环节,Agent 根据当前状态评估形势,分析可能的行动方案,为下一步决策提供依据。
- 行动(Action):根据推理结果,Agent 选择并执行具体的操作,将思考转化为实际动作。
- 观测(Observation):这是闭环中最关键的一步,是关键的反馈吸收阶段。行动执行后,Agent 收集环境反馈,评估执行效果,并将结果作为下一轮推理的输入,形成闭环。
传统的 LLM 容易在长路径任务中迷失方向,而 ReAct 的核心在于构建了一个不断自修正的逻辑闭环,引入了“动态重判断”机制:
容错性:如果 Action 的结果报错(Observation),Agent 会在下一轮 Thought 中意识到错误,并主动调整策略。
透明性:人类可以清晰地看到 Agent 的“内心独白”,理解它是如何从初始目标一步步逼近最终答案的。
终止判断:当 Observation 的结果已经足以回答问题时,Agent 会做出“无需再调用工具”的决策,直接输出 Final Answer,优雅地结束规划。
这种“推理-行动-观测”的循环,将原本死板的逻辑链路转化为了具有生命力的、可进化的工作流。
5. 预编排模式:Plan-and-Execute 下的自动化工程
在分析完侧重“边走边看”的 ReAct 模式后,我们必须讨论另一种在处理高复杂度、长链路、强依赖任务时表现更稳健的范式:Plan-and-Execute(规划与执行分离)。
5.1 核心运行机制
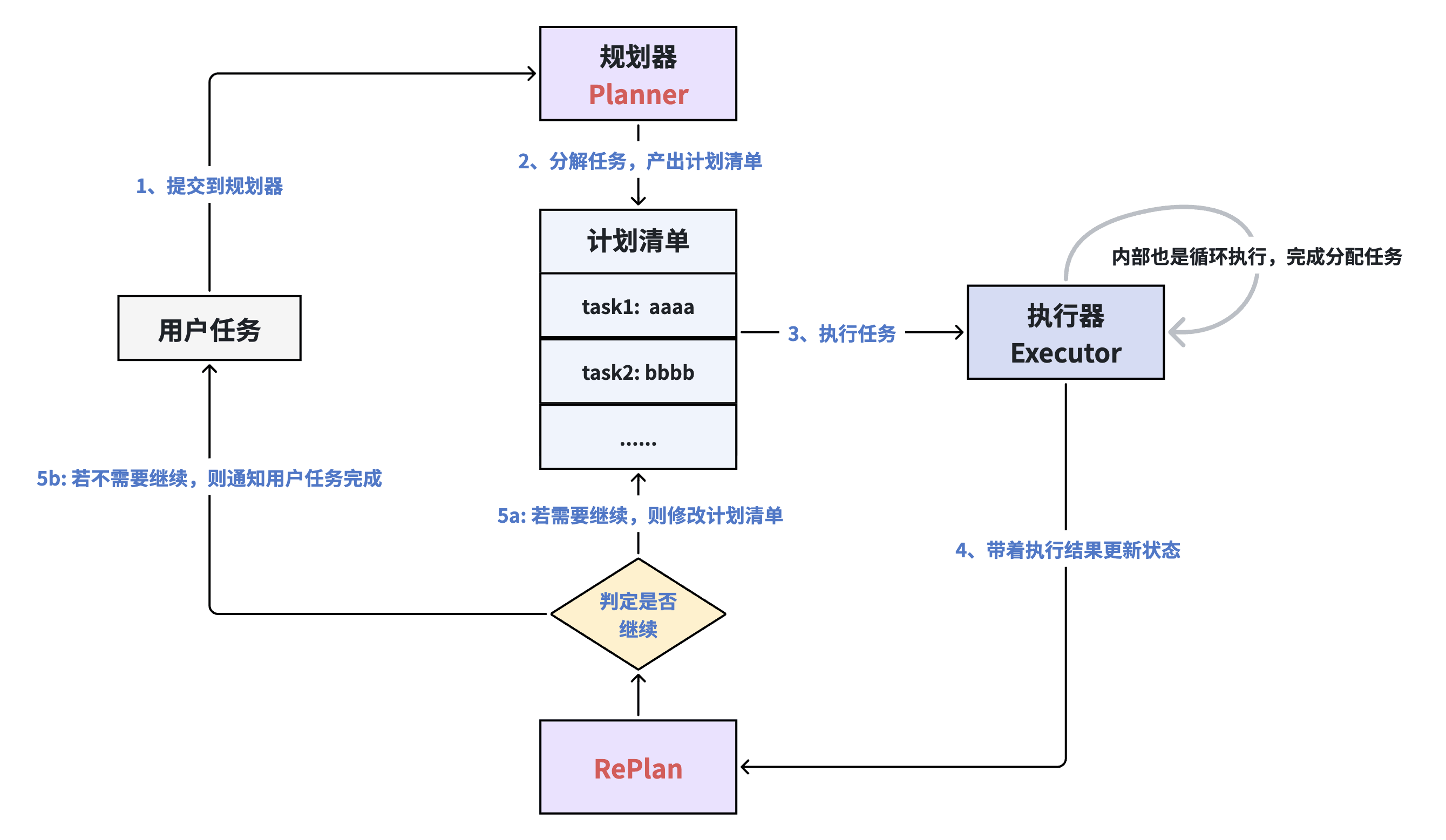
与 ReAct 将推理与行动混合在每一轮循环中不同,该模式通过一个显式的“计划清单”作为中转站,实现了决策与执行的解耦:
规划器:建立全局航向,当用户提交一个宏观任务(如“从零开发一个 NestJS 认证模块”)时,规划器首先介入。它利用最强模型的逻辑能力,将模糊的目标拆解为一系列结构化的 Task List。这一步是“谋定”的过程。
执行器:专注原子操作,执行器并不关心最终目标有多宏观,它只负责按照清单逐一执行。这种设计允许执行器内部进行自循环(Internal Loop),以最纯粹的方式利用工具完成特定的子任务。
重规划:动态闭环的关键,每完成一个子任务,系统会带着执行结果(Observation)进入重规划环节。此时,Agent 会面临一个关键判定:
需要继续:如果当前结果是中间产物,则修改计划清单,进入下一环。
不需要继续:如果目标已达成,则通知用户任务完成。
5.2 为什么在复杂场景中这种模式更具优势?
减少“推理漂移”:在 ReAct 模式下,模型容易因为每一步都要思考而逐渐忘记“初心”。Plan-and-Execute 通过一份全局可见的任务清单,锚定了长期目标。
上下文解耦:Executor 在执行第 5 个任务时,不需要关注第 1 个任务的详细推理过程,只需要关注第 4 个任务的输出。这极大节省了上下文空间,减少了因信息过载导致的幻觉。
高效重试:当任务执行失败时,系统只需要定位到清单中的特定索引进行重试或局部修正,而不需要从头开始整个推理链条。
5.3 小结
总的来说,Plan-and-Execute 模式并非排斥“边走边看”,而是通过架构上的解耦,为 Agent 注入了“工程师思维”:先出方案、逐项落实、节点复盘。
这一模式的精髓在于引入了重规划(RePlan)回路。正如流程图所示,它并不是在执行死板的脚本,而是在每一个关键步骤后都进行一次“判定是否继续”的元认知检查。这种机制有效地对抗了 LLM 的“瞬时记忆遗忘”,让 Agent 在面对需要跨越数十个步骤的自动化工程任务时,依然能保持航向的精准。
6. 范式选择:如何为你的 Agent 配置“小脑”?
在理解了 ReAct 与 Plan-and-Execute 后,开发者面临的核心挑战是如何在实际业务中进行选型。下表从工程实践角度对两者进行了对比总结:
| 维度 | ReAct | Plan-and-Execute |
|---|---|---|
| 规划时机 | 执行过程中实时推理 | 执行前进行全局拆解 |
| 错误处理 | 依赖下一轮 Thought 修正 | 依赖 RePlan 机制重修清单 |
| 适用广度 | 开放域交互、工具调用少 | 垂直域工程、长链路、强依赖 |
| 系统熵值 | 较高(状态随交互实时变化) | 较低(状态锚定在任务清单) |
7. 结语:规划是 Agent 迈向“确定性”的定盘星
至此,我们深度拆解了 Agent 规划模块的两大支柱:任务分解与自我反思。规划模块赋予了 Agent “逻辑”,但这仅仅是构建“数字员工”的第一步。一个能在复杂业务中持久生存的智能体,除了要懂得“如何思考”,还需要解决“我是谁、我做过什么、我从哪获取知识”的问题。在构建 Agent 时,并没有绝对的优劣之分。成熟的系统往往采用混合模式:在大目标上使用 Plan-and-Execute 保证方向不偏,在具体的子任务执行中开启 ReAct。
本篇文章到此结束,建议结合前文 《AI Agent 深度全景综述》 一起阅读,构建更完整的认知闭环。